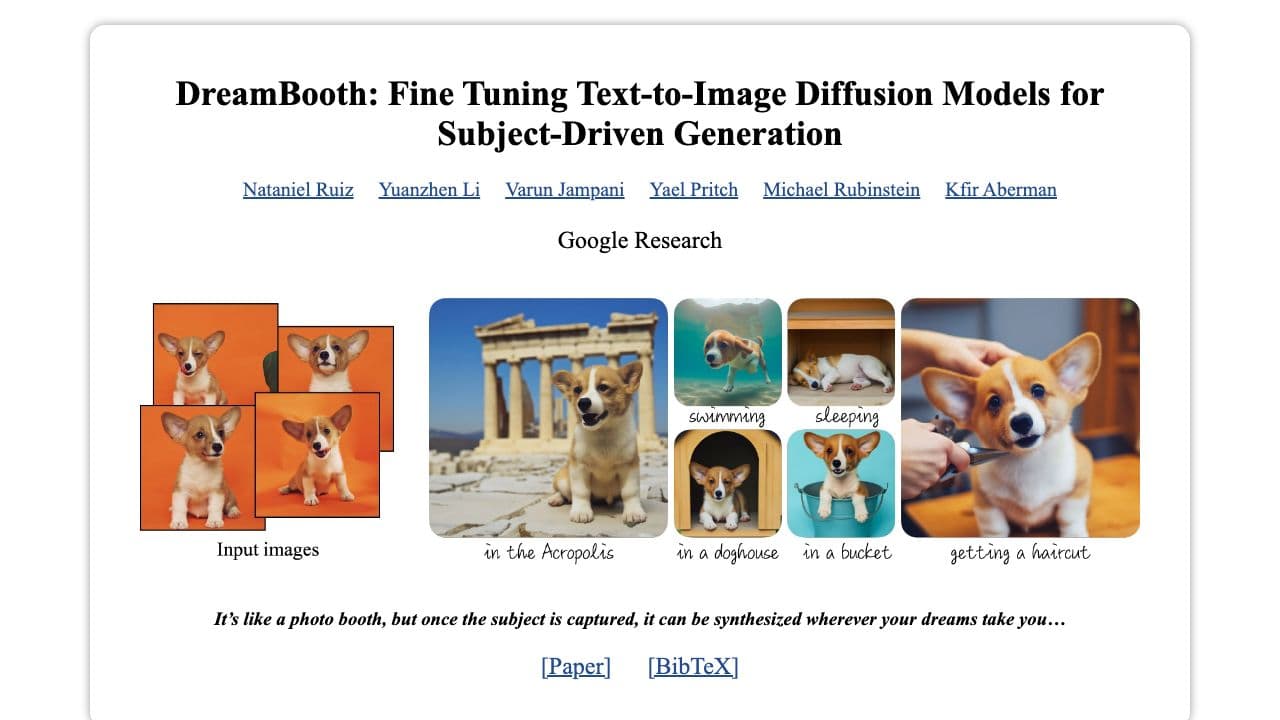
Research papers about the text-to-video model. A lot better than the first version of the Meta model.